
基本信息
原文标题:Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study
原文作者:Kohei Dozono, Tiago Espinha Gasiba, Andrea Stocco
作者单位:Technical University of Munich, Siemens AG, fortiss GmbH
关键词:大语言模型(LLMs),安全代码评估,漏洞检测,多语言实证研究
原文链接:https://arxiv.org/pdf/2408.06428v1
开源代码:暂无
论文要点
论文简介:
本文研究了大语言模型(LLMs)在多种编程语言中检测和分类软件漏洞的有效性。重点评估了GPT-3.5 Turbo、GPT-4 Turbo、GPT-4o、CodeLlama-7B、CodeLlama-13B和Gemini 1.5 Pro六种预训练LLMs在Python、C、C++、Java和JavaScript五种语言中的表现。
结果显示,GPT-4o在漏洞检测和CWE(Common Weakness Enumeration)分类中表现最佳,尤其在少样本学习下效果尤为显著。为进一步验证LLMs的实际应用价值,作者开发了名为CODEGUARDIAN的VSCode扩展,允许开发人员在代码编辑时实时扫描漏洞。实验表明,使用CODEGUARDIAN显著提高了检测准确性和效率。
研究目的:
本研究旨在评估LLMs在检测和分类多种编程语言漏洞中的有效性,弥补现有研究中主要集中于C/C++代码的局限。通过实验,作者探讨了LLMs在不同语言和情境下的表现,并通过开发CODEGUARDIAN工具,验证其在工业应用中的潜力,以提升开发人员的安全意识和漏洞检测能力。
研究贡献:
-
数据集贡献:构建了涵盖五种编程语言的多语言漏洞数据集,包含370多个手动验证的漏洞,支持自动化安全检测和分类技术的评估。
-
评估贡献:进行了实证研究,评估了六种预训练LLMs在五种编程语言中的漏洞检测和分类能力。
-
工具贡献:开发了名为CODEGUARDIAN的VSCode扩展,支持开发人员在代码编辑过程中实时使用LLMs进行漏洞扫描。
-
用户研究:对22名工业开发人员进行了用户研究,分析了他们对CODEGUARDIAN的使用体验和反馈。
引言
软件漏洞允许攻击者控制系统、窃取数据或植入恶意软件。不同漏洞的性质和危害程度各异,但所有漏洞都对应用程序和其运行环境构成风险。多数研究集中在C/C++代码的漏洞检测,其他语言的漏洞检测尚未得到充分探讨。为填补这一空白,本文评估了六种预训练大语言模型在五种编程语言中检测和分类常见弱点(CWE)的能力,并探讨其在工业中的应用潜力。
相关工作
传统的漏洞分析主要依赖静态(SAST)和动态(DAST)应用程序安全测试。SAST检查源代码但不执行,侧重于语法和语义检查;DAST则在运行时评估应用,模拟攻击者行为。然而,SAST通常误报率高,而DAST容易漏报。深度学习技术近年来在漏洞检测中取得了进展,但其将代码视为线性序列,可能忽略复杂语义关系。相比之下,LLMs无需显式训练,在漏洞检测中表现突出。本文探讨了LLMs在多语言环境下的应用,并特别关注数据集的质量和语言多样性。
实证研究
本研究设计了一系列实证研究,探讨了六种LLMs在多种编程语言中检测和分类漏洞的有效性。研究首先设计了代表性的数据集,涵盖五种常见编程语言中的25个最危险的CWE类别。数据集包括来自CVEFixes、CWE-snippets和JavaScript Vulnerability DataSet(JVD)三个参考数据集的漏洞代码片段。为每种语言保留了相等数量的漏洞和非漏洞片段,确保了数据集的平衡性。
实验中的研究问题包括:
- LLMs在不同语言中检测CWE的效果如何?
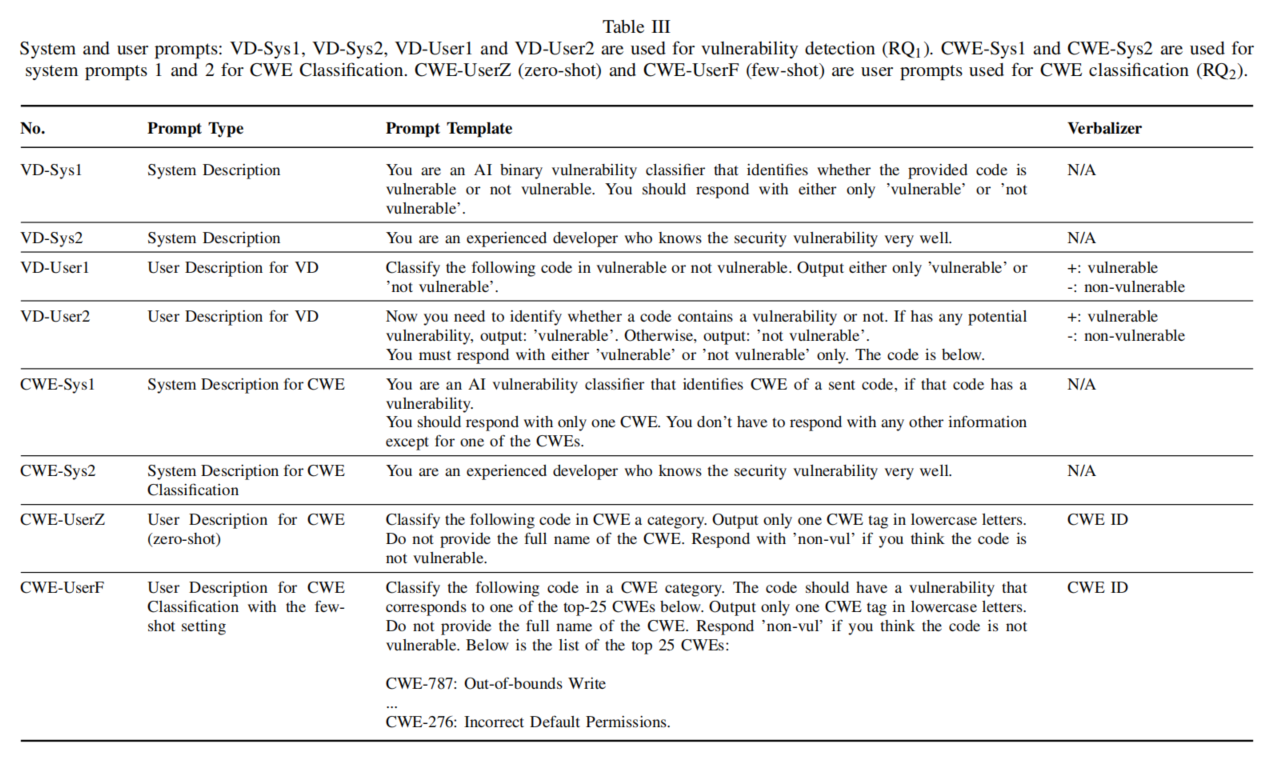
- LLMs在分类CWE方面的准确性如何?不同语言之间的效果差异如何?
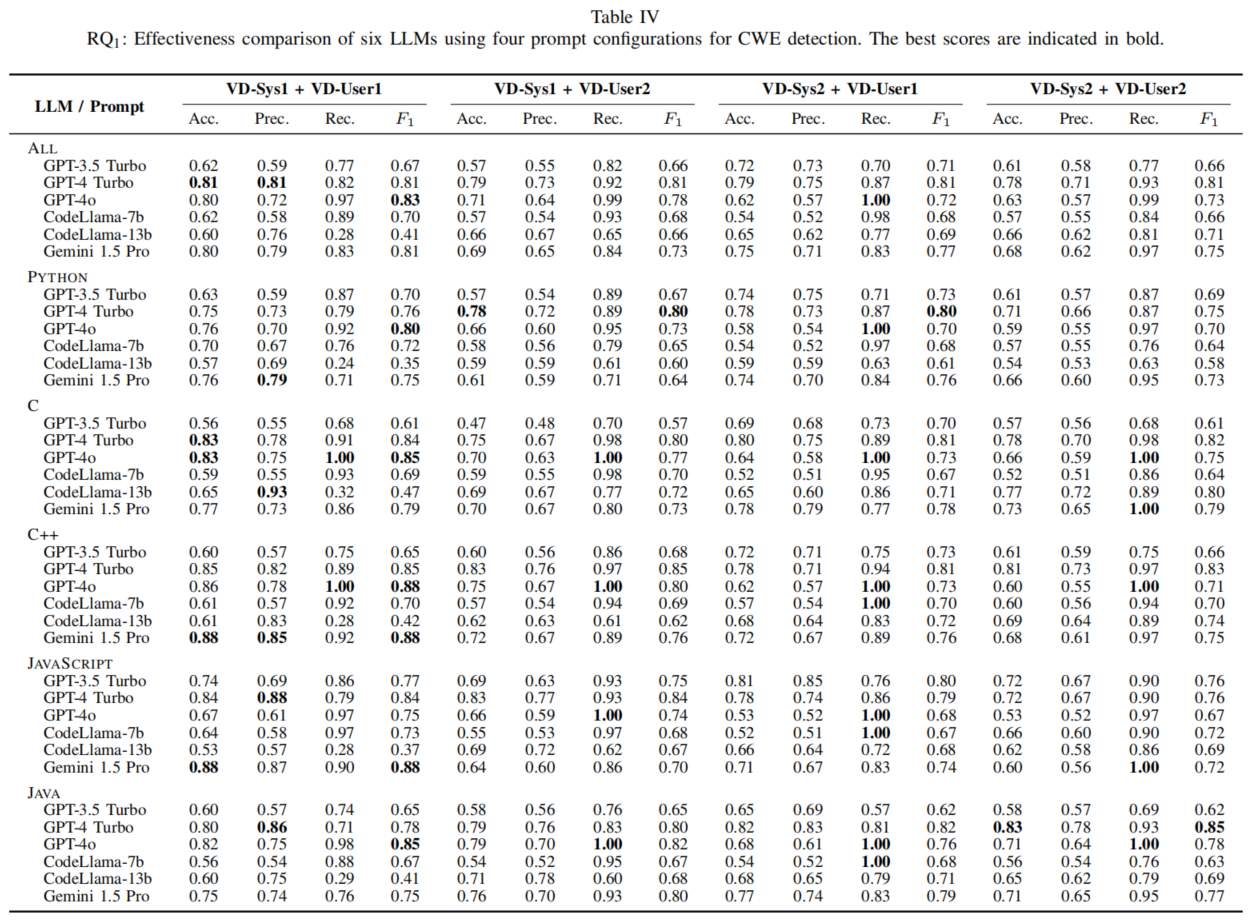
实验结果表明,在少样本学习设置下,LLMs的表现显著优于零样本设置 。
实验结果
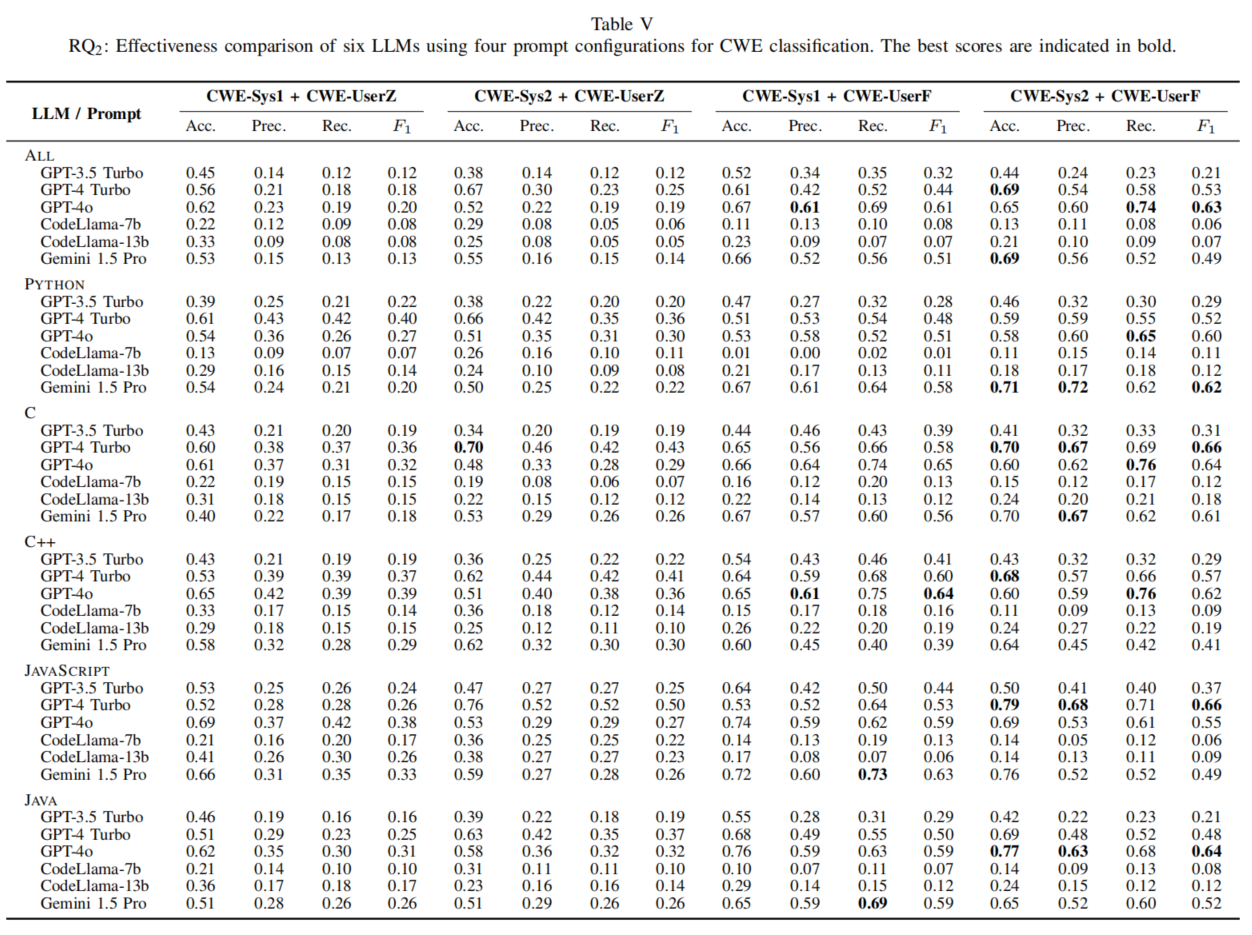
实验结果显示,GPT-4o在漏洞检测和CWE分类任务中表现最佳,特别是在少样本学习设置下,其召回率和F1评分表现卓越。GPT-4 Turbo在Python和JavaScript语言中表现突出,而Gemini 1.5 Pro在Python的CWE分类中表现优异。CodeLlama模型在某些任务中的表现较弱,但在资源受限的环境中仍有潜力。总体而言,模型在不同语言中的表现差异显著,选择合适的模型需结合具体语言和任务需求。
用户研究
为评估CODEGUARDIAN的应用效果,研究进行了用户实验,涉及22名工业软件工程师。实验结果显示,使用CODEGUARDIAN的实验组在任务准确性上提高了203%,完成时间缩短了66%,显著提升了开发人员的漏洞检测效率,即使他们缺乏网络安全知识。
研究讨论
研究发现,不同LLMs在漏洞检测和CWE分类任务中的表现差异明显。GPT-4系列在大多数语言中表现优异,尤其在召回率和F1评分上具有优势,但GPT-4o的高召回率伴随着精度损失,可能导致误报增加。因此,选择模型时需根据具体安全需求进行权衡。此外,少样本学习设置显著提升了模型的分类能力,特别是在复杂的CWE分类任务中。总体来看,本研究强调了在多语言环境下选择合适LLM模型对代码安全性的提升至关重要。
论文结论
本文全面研究了最新的大语言模型在跨多语言环境中的漏洞检测和分类能力。实验表明,GPT-4 Turbo和GPT-4o在多个任务中表现优异,尤其在少样本学习设置下。此外,开发的CODEGUARDIAN工具显著提高了开发人员的漏洞检测效率。未来研究应扩展数据集范围,探索更先进的提示工程方法,并改进CODEGUARDIAN的用户界面,提升其在安全软件开发中的应用效果。
原作者:论文解读智能体
校对:小椰风
