
本次分享论文:Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction
基本信息
原文作者:Sungmin Kang, Juyeon Yoon, Shin Yoo
作者单位:KAIST School of Computing, Daejeon, Republic of Korea
关键词:测试生成, 自然语言处理, 软件工程
原文链接:https://arxiv.org/pdf/2209.11515
开源代码: https://anonymous.4open.science/r/llm-testgen-artifact-2753
论文要点
论文简介:本文介绍了一个名为LIBRO的新型框架,该框架利用大语言模型(LLM)从BUG报告中自动生成测试用例,目的是实现BUG的有效复现。通过在Defects4J基准测试集上的应用,LIBRO成功地为多个项目生成了能够复现BUG的测试用例,展示了其在自动化测试生成领域的潜力和实用性。此外,LIBRO的方法论也为将来的自动化测试技术提供了新的研究方向和改进思路。
研究目的:本研究旨在解决软件开发中如何从BUG报告自动生成有效测试用例的问题。通过开发LIBRO框架,研究者试图提高软件测试的自动化水平,降低人力成本,并加速BUG修复过程,从而提升开发效率和软件质量。
研究贡献:
-
对开源代码库进行了分析,以验证从漏洞报告生成可复现漏洞测试用例的重要性;
-
提出了一个框架,利用大语言模型(LLM)来复现漏洞,并只在结果可靠时向开发者推荐生成的测试;
-
在两个数据集上进行了广泛的实证分析,表明研究者发现的模式,以及LIBRO的性能,是稳健的。
引言
在软件开发的过程中,自动化测试用例的生成是提高开发效率和软件质量的关键。现有的方法虽然在自动化测试生成领域取得了一定的进展,但从BUG报告自动生成精确的测试用例仍面临挑战。
为此,本文提出了一个利用大语言模型(LLM)来生成测试用例的新框架LIBRO。该框架通过解析BUG报告中的自然语言描述,自动构造出能够复现BUG的测试用例。LIBRO不仅增强了测试用例的生成能力,还通过实证研究证明了其在不同项目中的应用潜力和有效性。此研究为自动化测试和BUG复现提供了新的视角和方法。
研究动机
在当前的软件开发实践中,BUG复现测试的自动化生成是提高开发效率和软件质量的重要途径。然而,现有的自动化测试生成工具往往依赖于详尽的手动编写测试用例,这不仅耗时耗力,还可能因缺乏精确的BUG描述而无法准确复现BUG。
为了克服这些限制,研究者提出了LIBRO框架,该框架利用大语言模型直接从BUG报告中提取关键信息,自动生成可以复现BUG的测试用例。通过这种方式,研究者期望减少对人工输入的依赖,提高测试用例的生成效率和质量,进而支持更广泛的自动化调试技术的应用。
相关工作
为了更好地理解从BUG报告中生成测试用例的重要性和挑战,本文回顾了相关的研究工作。以往的研究主要集中在使用各种技术如符号执行、模型检查和搜索算法来自动化生成测试用例。这些方法虽然能够在一定程度上生成有效的测试用例,但通常需要详细的程序输入和严格的环境配置,限制了它们在处理自然语言描述的BUG报告时的效果和适用性。
此外,研究者还分析了现有工具在自动化生成测试用例时遇到的常见问题,如生成用例的精确性和覆盖率不足等。这些发现表明,需要一种新的方法来改进从BUG报告中直接生成测试用例的能力,从而更有效地支持软件开发和维护过程。
研究方法
本研究中,研究者开发了LIBRO框架,该框架采用大语言模型(LLM)以一种新颖的方式自动化生成测试用例。通过对BUG报告的自然语言描述进行分析和解析,LIBRO能够提取关键信息并构建测试用例。
这一过程包括对语言模型进行特定的训练和提示,使其能够理解和转化BUG描述中的技术细节。生成的测试用例随后经过一系列后处理步骤,如验证和优化,以确保它们能够有效地复现报告中的BUG。此方法的创新之处在于它结合了自然语言处理的最新进展和传统的软件测试技术,提高了测试用例生成的自动化水平和准确性。
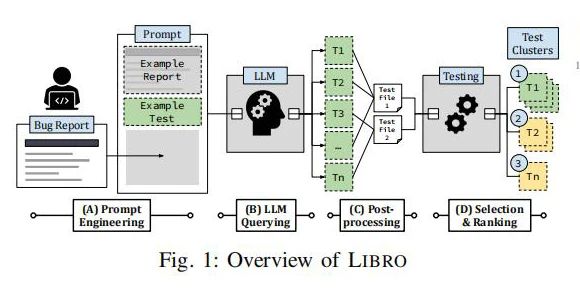
研究评估
研究者通过在Defects4J基准测试集和自建的报告-测试数据集上对LIBRO框架进行了详尽的实证评估。在Defects4J集上,LIBRO成功为251个BUG案例生成了可复现的测试用例,这表明它在所有测试BUG中有33.5%的成功率。
此外,通过比较不同项目间的测试成功率,研究者发现LIBRO在某些项目中的表现超过了50%,而在其他项目中则不足20%。这种差异揭示了LIBRO在处理不同类型和复杂度的BUG时的表现不一,指出了今后改进的方向。这些评估结果不仅证实了LIBRO方法的有效性,还为进一步优化框架提供了宝贵的数据支持。
研究问题
本研究主要探讨了如何有效利用大语言模型(LLM)从BUG报告中自动生成测试用例。研究者关注的问题包括:如何通过自然语言处理技术提取BUG报告中的关键信息,如何设计算法以确保生成的测试用例能够准确复现BUG,以及如何评估生成的测试用例在不同类型的软件项目中的适用性和有效性。这些问题的探索对于提高自动化测试的质量和效率具有重要意义。
实验结果
在应用LIBRO框架于Defects4J基准测试集后,研究者观察到LIBRO成功为33%的BUG案例生成了有效的复现测试用例。这些结果验证了使用大语言模型自动化生成测试用例的可行性。
然而,实验也显示,LIBRO在不同项目中的表现存在差异,某些项目中BUG复现的成功率高于其他项目。这一发现提示研究者未来需要进一步研究和改进LIBRO框架,以提高其在不同软件环境中的普适性和效果。
研究讨论
研究者讨论了LIBRO框架在实验中展示的性能及其潜在的局限性。尽管LIBRO在多个项目中有效地复现了BUG,但某些情况下的失败揭示了需要进一步优化的领域。例如,LIBRO在处理复杂或较少文档化的BUG报告时表现不佳。
此外,研究者分析了生成测试用例与BUG报告间的一致性问题,提出了增强模型理解能力和改进后处理策略的可能方向,以提高测试用例的准确性和复现效率。这些讨论为未来的研究和实践提供了宝贵的见解和指导。
论文结论
LIBRO框架成功展示了利用大语言模型生成测试用例的潜力,尤其在从BUG报告中自动化生成测试用例方面表现出色。通过实证研究,研究者验证了LIBRO在多个项目中的应用效果,发现其可以显著提升测试生成的自动化水平和效率。
尽管存在某些局限,未来的工作将集中在优化模型的理解能力和测试生成算法,以进一步提高测试用例的质量和BUG复现的成功率。此外,探索如何将这种方法应用于更广泛的软件测试场景也将是后续研究的重要方向。
原作者:论文解读智能体
校对:小椰风
