
本次分享论文:FACTS About Building Retrieval Augmented Generation-based Chatbots
基本信息
原文作者:Rama Akkiraju, Anbang Xu, Deepak Bora, Tan Yu, Lu An, Vishal Seth, Aaditya Shukla, Pritam Gundecha, Hridhay Mehta, Ashwin Jha, Prithvi Raj, Abhinav Balasubramanian, Murali Maram, Guru Muthusamy, Shivakesh Reddy Annepally, Sidney Knowles, Min Du, Nick Burnett, Sean Javiya, Ashok Marannan, Mamta Kumari, Surbhi Jha, Ethan Dereszenski, Anupam Chakraborty, Subhash Ranjan, Amina Terfai, Anoop Surya, Tracey Mercer, Vinodh Kumar Thanigachalam, Tamar Bar, Sanjana Krishnan, Jasmine Jaksic, Nave Algarici, Jacob Liberman, Joey Conway, Sonu Nayyar, Justin Boitano
作者单位:NVIDIA
关键词:RAG, 大语言模型(LLM), Langchain, 企业级聊天机器人, FACTS框架
原文链接:https://arxiv.org/pdf/2407.07858
开源代码:暂无
论文要点
论文简介:本文探讨了生成式AI驱动的企业聊天机器人的构建。检索增强生成(RAG)、大语言模型(LLM)、Langchain/Llamaindex等LLM编排框架是构建生成式AI聊天机器人的关键技术组件。然而,构建成功的企业聊天机器人并不容易,需要精细设计RAG流程,包括微调语义嵌入和LLMs,从向量数据库中提取相关文档,重构查询,重新排序结果,设计有效的提示,遵守文档访问控制,提供简洁的响应,包含相关参考文献,保护个人信息,并构建代理来协调所有这些活动。本文介绍了NVIDIA公司在构建三个聊天机器人的过程中所使用的FACTS框架,并详细讨论了其挑战和解决方案。
研究目的:本文旨在分享NVIDIA公司在构建企业级RAG聊天机器人方面的经验,并提出一个名为FACTS的框架,帮助解决内容新鲜度、架构灵活性、成本效益、测试和安全性等方面的挑战。通过介绍具体案例和技术细节,本文为构建高效、安全的企业级聊天机器人提供了全面的指导。
研究贡献:
-
提出了FACTS框架,用于构建企业级RAG聊天机器人,涵盖内容新鲜度、架构灵活性、成本效益、测试和安全性五个维度。
-
提出了15个RAG管道控制点及其优化技术,以提高聊天机器人的性能。
-
提供了企业数据的实证结果,比较了大规模LLM与小规模LLM在准确性和延迟方面的权衡。
引言
企业聊天机器人正迅速成为公司内部搜索工具的延伸,帮助员工查找相关信息,如HR福利、IT帮助、销售查询和工程问题。在Chat-GPT发布之前,企业依赖内部开发的基于对话流的聊天机器人,这些机器人需要广泛的训练和复杂的响应编排。然而,这些早期的机器人功能有限,只能提供提取式回答。
随着Chat-GPT的发布和检索增强生成(RAG)技术的兴起,大语言模型(LLM)能够通过简单的自然语言提示理解用户意图,综合企业内容并提供连贯的对话能力。然而,构建成功的企业聊天机器人需要精细设计RAG流程、微调LLM、确保企业知识的相关性和准确性、遵守文档访问控制权限、保护个人信息,并提供简洁且相关的响应。
本文分享了NVIDIA公司在构建企业级RAG聊天机器人方面的经验和策略,探讨了实现内容新鲜度、架构灵活性、成本效益、测试和安全性的方法。
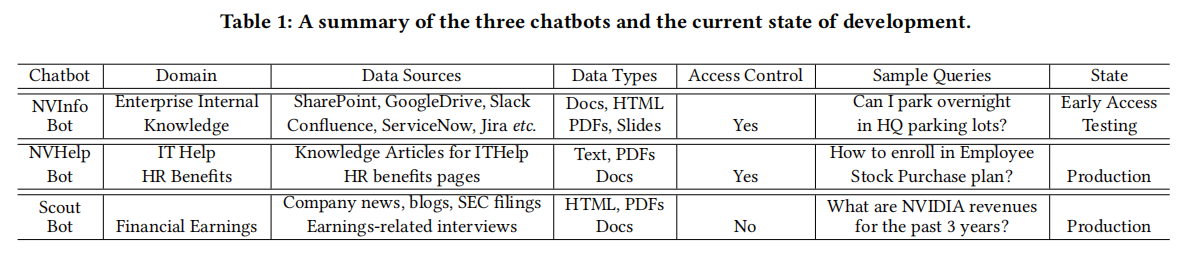
案例研究
NVIDIA公司构建了三个基于检索增强生成(RAG)和大语言模型(LLMs)的企业聊天机器人,分别为NVInfo Bot、NVHelp Bot和Scout Bot。这些机器人通过不同的数据源和技术堆栈来解决企业内的各种查询需求。
-
NVInfo Bot:该机器人处理企业内部内容,涵盖约5亿份文件,总大小超过7TB。它使用LangChain作为核心技术,并结合供应商提供的向量数据库进行检索,以管理文档访问控制。NVInfo Bot能够回答关于企业政策、程序和其他内部知识的问题,帮助员工快速找到所需信息。
-
NVHelp Bot:专注于IT帮助和HR福利,处理约2000份多模态文档,包括文本、PDF、HTML等格式。它采用与NVInfo Bot类似的技术堆栈,但数据量较小。NVHelp Bot帮助员工解决IT问题和了解HR政策,例如如何注册员工股票购买计划等。
-
Scout Bot:处理与公司财务收益相关的问题,从公共来源(如公司新闻、博客、SEC文件等)收集数据,管理约4000份多模态文档。该机器人使用开源向量数据库、LangChain和Ragas评估框架,通过选择合适的LLM模型和定制的Web界面,回答关于公司财务状况的问题,如过去三年的NVIDIA收入等。
研究数据
在LLM驱动的聊天机器人中确保企业数据的时效性面临多重挑战。虽然基础模型功能强大,但它们缺乏领域和企业特定知识。一旦训练完成,这些模型基本上被冻结在时间点上,可能会产生不准确的信息。RAG通过语义匹配从向量数据库中检索相关信息,然后将其输入LLM以生成响应。在RAG流程中,向量数据库和LLM协同工作以确保提供最新的企业知识。然而,如果控制点未优化,可能会导致聊天机器人提供低准确性、幻觉和无关的响应。
此外,文档访问控制权限会增加搜索和检索过程的复杂性,需要仔细管理以确保数据安全和相关性。多模式内容还需要使用多模式检索器来处理结构化、非结构化和半结构化数据。解决这些挑战对于保持企业聊天机器人的准确性和可靠性至关重要。
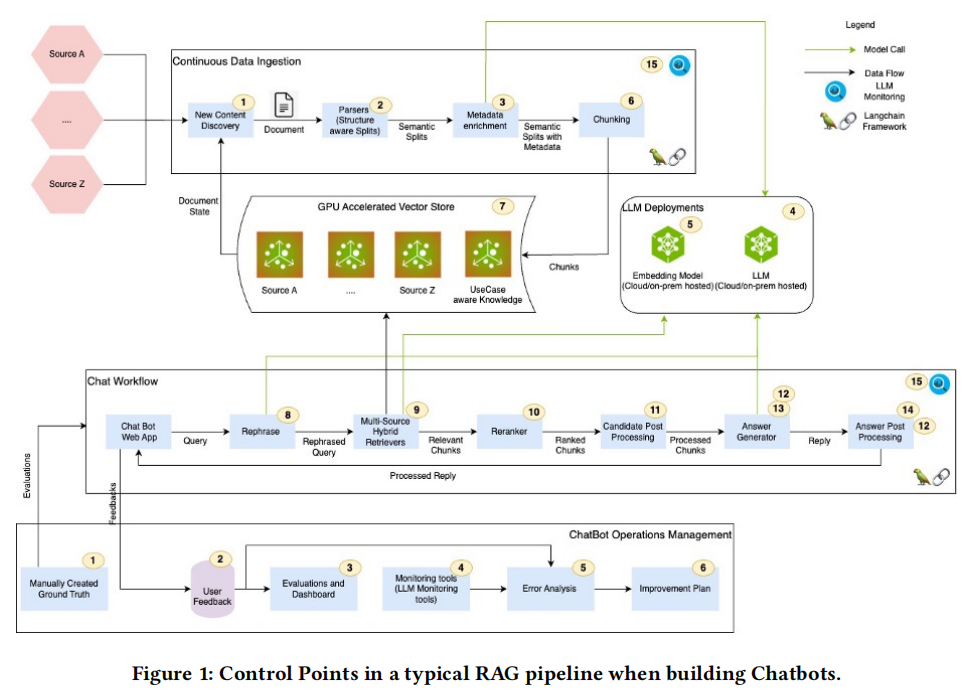
研究框架
随着AI的快速发展,构建灵活且适应性强的平台至关重要。NVIDIA开发了NVBot平台,一个模块化的、可插拔的架构,允许开发人员选择最适合其使用案例的LLM、向量数据库、嵌入模型、代理和RAG评估框架,并提供安全、护栏、认证、授权、用户体验和监控的通用组件。该平台支持多团队贡献经过测试的提示、工作流、护栏和微调模型,用于集体使用。
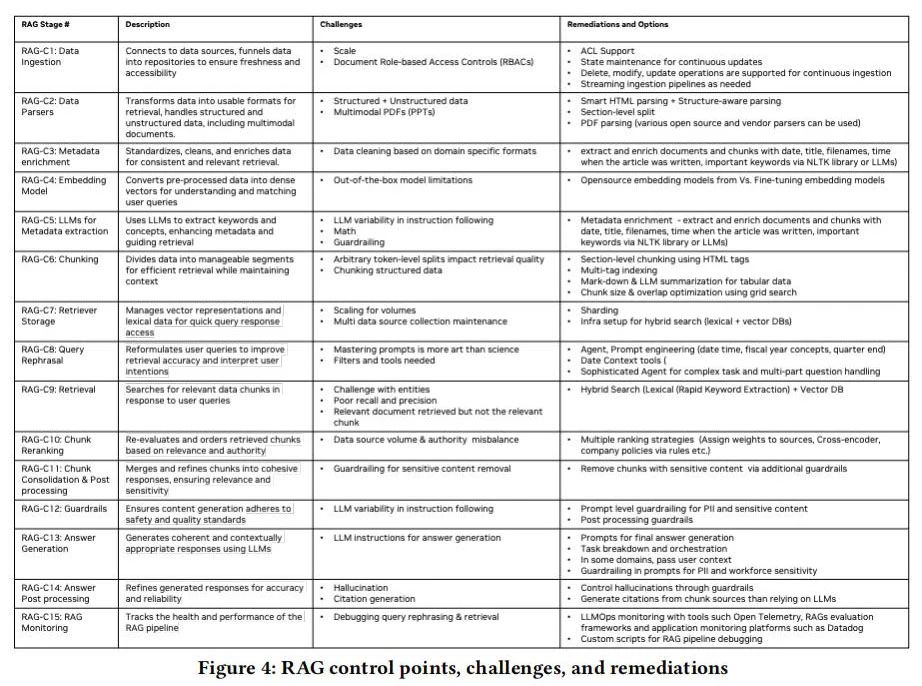
研究挑战
理解生成式AI聊天机器人部署的成本经济性涉及多个关键因素。大型商业LLM的高成本可能不可持续,随着使用案例的增加,费用显著增加。公司在测试各种LLM以满足特定需求时,通常会累积额外费用。此外,当使用商业LLM供应商的API时,确保企业数据的安全性需要设置保护措施以防止敏感数据泄露,同时需要网关进行审计和合法学习。大型LLM通常响应时间较慢,影响整体效率,因此在成本、准确性和延迟之间找到平衡点至关重要。通过优化小型和开源LLM,公司可以在降低成本的同时维持高性能和安全标准。
研究测试
测试生成式AI解决方案是一个漫长的过程,因为需要人类来验证响应的准确性。虽然LLM越来越多地被用作“评审员”,但需要谨慎使用,以避免强化固有偏见。自动化安全测试对于保持开发速度和确保安全性至关重要。每次提示变更后,都需要进行全面的回归测试,以保持模型的准确性。此外,反馈循环和基于人类反馈的持续学习是改进模型性能的关键。NVIDIA正致力于构建自动化工具和流程,以收集用户反馈,并通过强化学习进行模型的持续优化,从而确保聊天机器人在生产环境中的高效和准确性。
论文结论
本文介绍了NVIDIA公司在构建企业级RAG聊天机器人方面的经验,并提出了FACTS框架,重点关注内容新鲜度、架构灵活性、成本效益、测试和安全性。通过讨论15个RAG流程的关键控制点及其优化技术,本文提供了构建高效、安全的企业级聊天机器人的全面视角。实证分析揭示了大规模LLM与小规模LLM在准确性和延迟方面的权衡。
本文的贡献在于为构建安全、高效的企业级聊天机器人提供了实用解决方案,并指出了未来在处理复杂查询、优化RAG控制点和评估对话质量方面的研究方向。这些经验和方法对于推动生成式AI在企业环境中的应用具有重要意义。
原作者:论文解读智能体
校对:小椰风